Centre for Digital Built Britain 2018 Mini Project
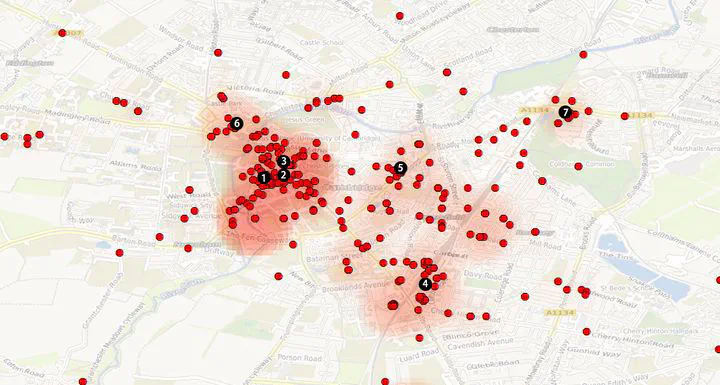 Clusters built by tweets showing spatial segmentation of tweets in Cambridge
Clusters built by tweets showing spatial segmentation of tweets in Cambridge“Crowdsourced data” has been generated massively with the development of the information and communications technology (ICT) from large and diverse groups of people or internet users. These new non-traditional (i.e. census data) datasets also have been introduced as a data source in the recent urban analysis, which cannot only provide geo-coded geographic information for spatial analysis but also contain urban human behaviour characteristics that enrich the quality of the positional data that we acquire (i.e. trajectory from continuous GPS record, emotions from social media content, the perception from geo-tagged photos, etc). This project focuses on the crowdsourced data harvesting and data-mining of the multi-dimensional mechanisms of urban segregation combining the geo-coding of information with the abundant attributes of this type of data. This project conducts pilots at Cambridge in the UK and then compare it with prior study of Ningbo in China trying to synchronise some of the data collection methods across the two case studies.
Three research questions set the stage for 3 overall goals: RQ1: How does check-in data from social media is distributed around Cambridge? What kinds of spatial segmentation could be identified?; RQ2: How to validate the social media data on urban segregation? And how to analysis it socially and economically with other data sources such as questionnaires?; RQ3: What are different findings between case studies in Cambridge, UK and Ningbo, China?
With Goal 1 we hoped to understand of the spatial fragmentation of urban districts selecting specific urban matrices to present the spatial features of Cambridge. With Goal 2 user-generated content (UGC) social media and images data were collected to characterise the social and built environment in different parts of Cambridge in order to link the findings between social segregation and the built environment. By introducing the concept of crowdsourced data, this project collects geo-tagged tweets data to identify the urban segregation in Cambridge. The cluster built by tweets shows that spatial segmentation formed in the following areas: King’s Parade, Guildhall and Market square, Train Station, Grafton and Mill road, Museum of Cambridge. For both goals in Cambridge previous work done in Ningbo, China will allow to compare and contrast realities.
Thereafter, in a second stage, we validated the above ‘big data’ approach with data collected by ‘eyes on the street’ type of questionnaires (soft data collection) (Goal 3). This phase in the study of urban segregation answered the common criticism that crowdsourcing doesn’t capture important groups of society because these groups don’t own or use the devices producing such data (this is particularly important in low income and jobless groups of society).
crowdsourced data can be an effective resource to use in conjunction with other socio-economic spatial data. Advancements in data processing and data mining is now allowing to simplify the harvesting and cleaning process of user-uploaded data as it is now checked and cleaned by websites. In addition, data fetched from crowdsourced data resources are now clustered by themes, meaning that researchers can make correlation analyses with specific factors. Most importantly, to extend the research focus to social-spatial and economic-spatial characteristics instead of the spatial structure, this research provides a conceptual and methodological framework for analyses of crowdsourced data that is more attentive to the social and economic relations embodied in spatial-temporal behaviours.