断尾回归分析(Tobit Analysis)
Toobit Analysis也被称为截尾回归模型或删失回归模型(censored regression model),属于受限因变量(limited dependent variable)回归的一种。
Censored data 删失数据
Censoring的定义是:a condition in which the value of a measurement or observation is only partially known. 主要有以下几种类型的censoring:
Left censoring– a data point is below a certain value but it is unknown by how much.Interval censoring– a data point is somewhere on an interval between two values.Right censoring– a data point is above a certain value but it is unknown by how much.
删失数据的例子
Example 1. In the 1980s there was a federal law restricting speedometer readings to no more than 85 mph. So if you wanted to try and predict a vehicle’s top-speed from a combination of horse-power and engine size, you would get a reading no higher than 85, regardless of how fast the vehicle was really traveling. This is a classic case of right-censoring (censoring from above) of the data. The only thing we are certain of is that those vehicles were traveling at least 85 mph.
Example 2. A research project is studying the level of lead in home drinking water as a function of the age of a house and family income. The water testing kit cannot detect lead concentrations below 5 parts per billion (ppb). The EPA considers levels above 15 ppb to be dangerous. These data are an example of left-censoring (censoring from below).
Example 3. Consider the situation in which we have a measure of academic aptitude (scaled 200-800) which we want to model using reading and math test scores, as well as, the type of program the student is enrolled in (academic, general, or vocational). The problem here is that students who answer all questions on the academic aptitude test correctly receive a score of 800, even though it is likely that these students are not “truly” equal in aptitude. The same is true of students who answer all of the questions incorrectly. All such students would have a score of 200, although they may not all be of equal aptitude.
Censored data 删失数据和 trancated data 截断数据的差别
- With censored variables, all of the observations are in the dataset, but we don’t know the “true” values of some of them.
- With truncation some of the observations are not included in the analysis because of the value of the variable.

截断数据的例子
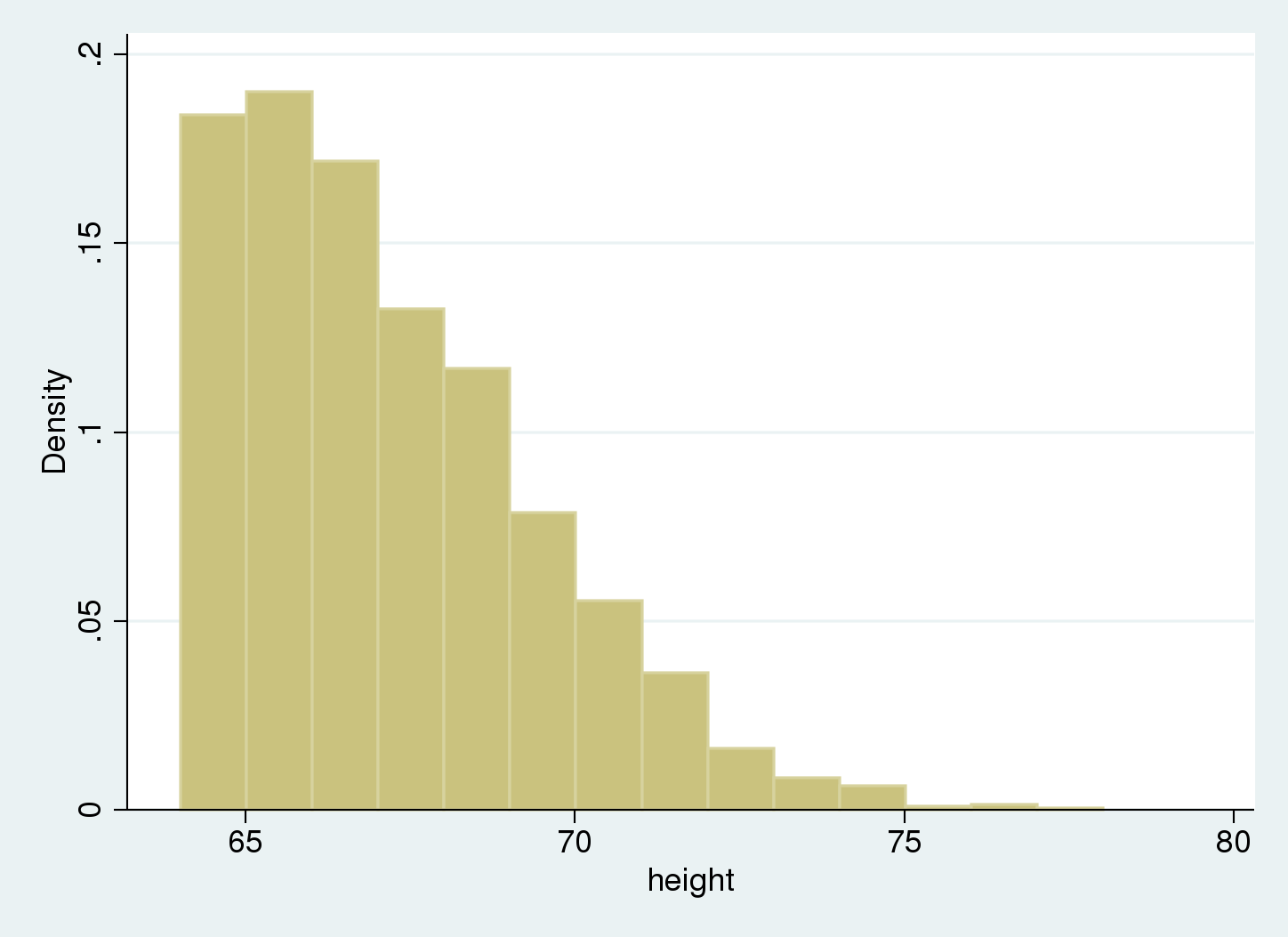
- Fogel et al. (1978) published a dataset on the height of Royal Marines that extends over two centuries. It can be used to determine the mean height of men in Britain for different periods of time. Trussell and Bloom (1979) point out that the sample is truncated due to minimum height restrictions for the recruits. The data are truncated (as opposed to censored) because individuals with heights below the minimum allowed height do not appear in the sample at all. To account for this fact, they fit a truncated distribution to the heights of Royal Marines from the period 1800–1809.
Tobit Analysis 在R中实现
具体教程参看UCLA的IDRE Stats – Statistical Consulting的教程。
summary(m <- vglm(apt ~ read + math + prog, tobit(Upper = 800), data = dat))
Reference
牛海沣
副研究员
英国剑桥大学土地经济系副研究员,欧盟Horizon 2020资助项目Emotional Cities空间分析研究员。主要研究兴趣包括城市大数据挖掘、空间数据科学、地理可视化、城市感知和城市动态模拟,特别是关注如何通过结合机器学习、人工智能和城市大数据来更好地支持城市规划、政策制定和智能管理。